TIDEE: Tidying Up Novel Rooms using Visuo-Semantic Commonsense Priors
Gabriel Sarch Zhaoyuan Fang Adam W. Harley Paul Schydlo
Michael Tarr Saurabh Gupta Katerina Fragkiadaki
ECCV 2022
*2023 CVPR Embodied AI Workshop Rearrangement Challenge winner*

Abstract
We introduce TIDEE, an embodied agent that tidies up a disordered scene based on learned commonsense object placement and room arrangement priors. TIDEE explores a home environment, detects objects that are out of their natural place, infers plausible object contexts for them, localizes such contexts in the current scene, and repositions the objects. Commonsense priors are encoded in three modules: i) visuo-semantic detectors that detect out-of-place objects, ii) an associative neural graph memory of objects and spatial relations that proposes plausible semantic receptacles and surfaces for object repositions, and iii) a visual search network that guides the agent’s exploration for efficiently localizing the receptacle-of-interest in the current scene to reposition the object. We test TIDEE on tidying up disorganized scenes in the AI2THOR simulation environment. TIDEE carries out the task directly from pixel and raw depth input without ever having observed the same room beforehand, relying only on priors learned from a separate set of training houses.
Human evaluations on the resulting room reorganizations show TIDEE outperforms ablative versions of the model that do not use one or more of the commonsense priors. On a related room rearrangement benchmark that allows the agent to view the goal state prior to rearrangement, a simplified version of our model significantly outperforms a top-performing method by a large margin.
Overview
How does TIDEE work?
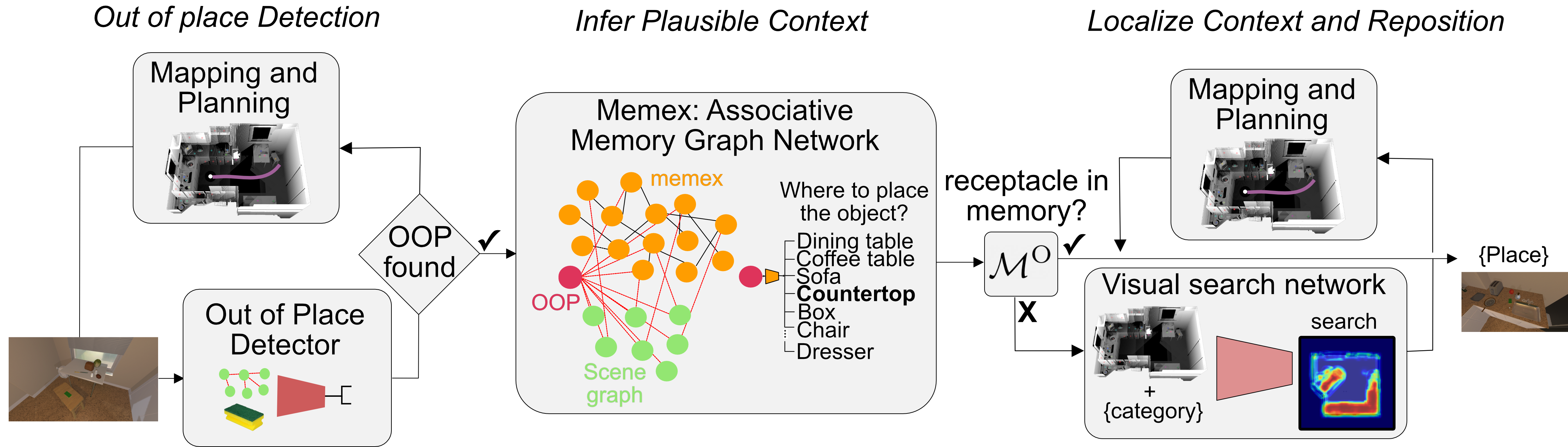
TIDEE can clean up never-before-seen rooms without any instruction or previous exposure of the room and object instances. TIDEE does this by exploring the scene, detecting objects and classifying whether they are in place or out of place. If an object is out of place, TIDEE uses graph inference in its joint external graph memory and scene graph to infer plausible receptacle categories. It then explores the scene guided by a visual search network that suggests where a receptacle category may be found, given the scene spatial semantic map.
Results
TIDEE outperforms ablative versions of the model that do not use one or more of the commonsense priors. The table below shows the percent of human evaluators that prefer TIDEE over the baselines (mean ± standard deviation across subjects (n=5),*p<0.05, **p<0.01, Binomial test).

TIDEE generalizes zero-shot to the recent scene rearrangement benchmark, which considers an AI agent tasked with repositioning objects in a scene in order to match the prior configuration. TIDEE outperforms the current state of the art by a significant margin on the 2022 rearrangement benchmark (as of July 2022).
We have submitted our model to the rearrangement leaderboad here:
content_copy Citation
@inproceedings{sarch2022tidee,
title = "TIDEE: Tidying Up Novel Rooms using Visuo-Semantic Commonsense Priors",
author = "Sarch, Gabriel and Fang, Zhaoyuan and Harley, Adam W. and Schydlo, Paul and Tarr, Michael J. and Gupta, Saurabh and Fragkiadaki, Katerina",
booktitle = "European Conference on Computer Vision",
year = "2022"}Thanks to Dave Epstein for the webpage template!